Ok, What is a knowledge graph?
The term “knowledge graph” is used in different ways, often leading to confusion. Sometimes, people refer to Google’s Knowledge Graph — the massive, behind-the-scenes system of entities that powers search. Other times, they mean a knowledge graph — something you can actually build for your own website using schema markup. In yet another case, the term is misapplied to the knowledge panel — the visible box that appears in Google results.
Sorting these out matters, especially if you’re a business owner or SEO professional trying to understand how entities affect visibility online. In this article, we’ll break the concept into its three main uses and show how each one connects to search and strategy.
The Three Meanings of “Knowledge Graph”
Before we go further, it’s important to separate the three different ways people use the term “knowledge graph”:
- The Knowledge Graph (capitalized) – Google’s proprietary system of entities and relationships that powers how search understands meaning.
- A knowledge graph (lowercase) – a graph you can build for your own website or organization using schema markup and entity connections.
- The knowledge panel – the visible search result box that many people mistakenly call a “knowledge graph,” even though it’s actually just an output of Google’s graph.
‘The Knowledge Graph’: Google’s Hidden Web of Entities
When Google announced ‘The Knowledge Graph’ in 2012, it marked a fundamental shift in how information is processed. Instead of seeing the web only as documents filled with keywords, Google began interpreting it as a network of entities — people, places, organizations, products, and ideas — and the relationships that tie them together.
The important thing to understand is this: Google’s Knowledge Graph dictates how everything else is understood.
- It’s proprietary. The full contents are undisclosed. Only Google knows exactly which entities and connections exist inside.
- It’s entity-first. Rather than reading queries as strings of text, Google interprets them through the lens of entities and their attributes.
- It powers results. From knowledge panels to featured snippets, from “People Also Ask” to voice assistant answers — they all rely on the structure of the Knowledge Graph.
Think of it as the operating system of meaning for Google. Every time you search, Google consults its Knowledge Graph to interpret your intent and decide which results to serve.
For business owners and SEO professionals, this means that visibility is no longer just about keywords — it’s about whether Google recognizes your business as an entity, how it connects you to other entities, and where you fit into the broader graph.
2. A Knowledge Graph: Building One for Your Business
While Google’s Knowledge Graph is out of reach, you can build a knowledge graph for your own website or organization. This is where business owners have real leverage. By structuring your data in a way that mirrors how Google thinks, you give search engines a clearer, stronger signal of who you are and how you fit into the bigger picture.
But not all knowledge graphs are equal. In fact, most websites don’t build true graphs at all. Instead, they fall somewhere along a spectrum of comprehensiveness — from barebones structured data to a fully interconnected semantic graph.
Feature 1: The Three Phases of a Knowledge Graph
The diagram below illustrates the three phases of sophistication a site’s knowledge graph can take:
- Entity Catalog (the weakest form)
- Knowledge Repository (a partial structure)
- Knowledge Base / Knowledge Graph (the real goal)
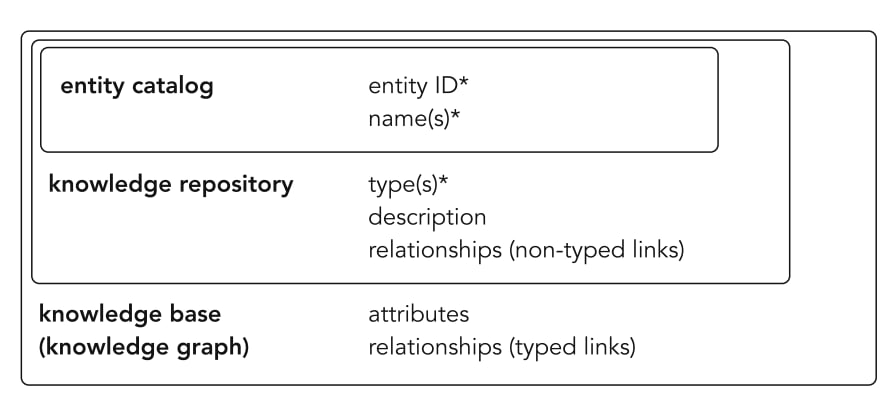
Each phase builds on the one before it. A knowledge base contains everything a repository does, and a repository contains everything a catalog does. The difference is in comprehensiveness and connectivity — how far you go in identifying, describing, and linking your entities.
1. Entity Catalog
This is the starting point — and for many sites, it’s as far as they go.
- Entities (like your company, services, or products) are simply named, sometimes without unique IDs.
- Schema might exist, but it’s shallow: no interconnections, no IDs, no real structure.
- This isn’t a knowledge graph; it’s a list.
Many businesses stop here because they’ve “added schema,” but all they’ve really built is a catalog. They will say they are doing “Entity SEO,” but it’s no more than a bag-of-words approach.
2. Knowledge Repository
A step up, where entities start to gain more meaning:
- Entities have names, types (Person, Organization, Place, Product), and descriptions.
- Relationships are mentioned (e.g., “Company employs Person”), but they aren’t typed or linked to authoritative IDs.
- The missing piece here is the pointer — a stable identifier (often a URL or @id) that anchors a relationship to a specific entity.
Without pointers, relationships are vague. With them, entities become anchored in a larger ecosystem.
3. Knowledge Base (a true knowledge graph)
This is where structured data matures into an actual graph.
- Entities are properly named, identified, and assigned unique IDs.
- Attributes are well-defined, and relationships are typed and anchored with pointers.
- The entities connect across your entire website, forming a semantic network — much like how internal linking strengthens your content structure.
Just as a site with poor internal linking is weaker in Google’s eyes, a “repository” without typed links and pointers is weaker than a full graph. A true knowledge graph weaves everything together into a web of meaning.
Why This Matters
When you build at the entity catalog level, you’re giving Google a pile of names.
At the repository level, you’re offering more context — but the connections are fragile.
Only at the knowledge base level do you give search engines what they really want: a durable, connected, machine-readable understanding of your business.
3. The Misnomer: Knowledge Graph vs. Knowledge Panel
One of the biggest sources of confusion is that many people use the term knowledge graph when what they actually mean is the knowledge panel.
A knowledge panel is the visible box of information that appears in Google search results — usually on the right-hand side of desktop or at the top on mobile. It might display:
- A business’s name, logo, and description.
- Key facts about a person or organization.
- Links to social profiles or websites.
- Reviews, contact details, or other structured information.
But here’s the distinction:
- The knowledge panel is an output, not the graph itself.
- It’s a visual reflection of how Google has connected your entity across multiple sources (its Knowledge Graph, Wikipedia, Wikidata, business listings, schema markup, and more).
- The panel shows users the results of Google’s entity understanding — but the underlying graph is what dictates what appears there.
Why the Distinction Matters
Understanding these three uses of the term “knowledge graph” isn’t just semantics — it’s strategy.
- The Knowledge Graph is Google’s system. It dictates how everything is understood. You can’t see it or edit it, but you can influence it.
- A knowledge graph is what you build for your business. It’s your chance to structure your entities and relationships in a way that Google can interpret clearly.
- The knowledge panel is the outcome. It’s the visible proof that Google has recognized your entity and connected it properly.
For business owners and SEOs, the progression is clear:
- Build your own knowledge graph (knowledge base).
- Use schema, IDs, and pointers to reinforce your entities.
- Increase the likelihood that Google incorporates this into The Knowledge Graph.
- Earn a knowledge panel that accurately represents your brand.
Common Misunderstandings
Is schema markup the same thing as a knowledge graph?
Not exactly. Schema is the language you use to build a knowledge graph. Without IDs, typed links, and pointers, schema alone can stay at the “catalog” level.
Can I guarantee a knowledge panel for my business?
No. Panels are generated at Google’s discretion. But a robust knowledge graph dramatically increases your odds.
Does every business need a knowledge graph?
Strictly speaking, no. But in today’s search landscape, where Google is moving from strings to things, having a graph is no longer optional if you want to be fully understood.
Conclusion
So, again what is a knowledge graph?
At its highest level, The Knowledge Graph is Google’s undisclosed entity system — the massive semantic infrastructure that dictates how all information online is understood. It connects billions of entities through typed edges, storing facts in a way that transforms raw data into meaning. This unseen knowledge base drives results, powers panels, and fuels the entire ecosystem of search.
But a knowledge graph is also something you can build yourself. For a business, it’s not abstract — it’s a practical data model. You create entities, define attributes, and link them with meaningful relationships. When you evolve from an entity catalog into a true knowledge base, you’re no longer just stacking disconnected data points. You’re forming graphs of knowledge, with typed links that resemble how Google itself stores and retrieves meaning.
- Entity catalog → repository → knowledge base: a tiered journey from names, to context, to understanding.
- Pointers and IDs: the critical difference between a weak repository and a durable knowledge graph.
- Internal linking and external alignment: just as links connect your pages, IDs and edges connect your graph.
A big part of this is understanding the difference between “just schema” and a structured graph database approach. In a simple repository, you might describe an entity but never connect it to anything. In a full knowledge graph, you go further:
- You use pointers to stabilize meaning.
- You align with external databases like Wikidata.
- You establish edges between nodes that create a connected graph data fabric.
For many, this is where the confusion sets in: the knowledge panel. The panel is not the graph — it’s the output. It’s a curated display that pulls from knowledge graphs, repositories, and other data sources. While users see the summary box, search engines are operating on the full semantic layer underneath.
- The knowledge panel = storefront.
- The knowledge graph = warehouse.
- Both matter, but only one determines what shows up in search.
This distinction is critical for modern SEO. When you build knowledge graphs for your own site, you do more than mark up data — you align with how artificial intelligence and data science systems actually interpret the web. You prepare your content for graph analytics, where search engines measure relevance by how well-connected your entities are. You give them clear, machine-readable graphs that can be analyzed, queried, and explored.
Different types of graphs can even apply depending on your needs. For example:
- Property graphs emphasize attributes and edges in ways that resemble business logic.
- RDF knowledge graphs emphasize semantic clarity and interoperability.
- Both are effective for structuring data models that search engines can read and reason over.
Ultimately, when you stop at an entity catalog, you give Google names. When you create a repository, you give it context. But when you create a true knowledge graph, you give it understanding — the kind of structured clarity that search engines reward.
By seeing these distinctions clearly, you can move from “adding schema” to actually building a semantic framework. And when you build meaning instead of fragments, you make it easier for Google — and for users — to:
- Explore your content more deeply.
- Run analysis across your structured graphs.
- Store and retrieve your entity data reliably.
- Recognize your business as a trusted entity.
That’s the real power of knowledge graphs — they don’t just describe, they connect, and in doing so, they define authority in the modern web.